Low-level visual perception (LLVP) is important for multimodal LLMs. Are MLLMs capable of it? We introduce Euclid, a family of models trained on high-fidelity synthetic visual descriptions to improve LLVP ability of MLLMs.

Abstract
MLLMs have made rapid progress in recent years, yet continue to struggle with low-level visual perception (LLVP)---particularly the ability to accurately describe the geometric details of an image. This capability is crucial for applications in areas such as robotics, medical image analysis, and manufacturing. In this paper, we first introduce Geoperception, a benchmark designed to evaluate an MLLM’s ability to accurately transcribe 2D geometric information from an image. Using this benchmark, we demonstrate the limitations of leading MLLMs, and then conduct a comprehensive empirical study to explore strategies for improving their performance on geometric tasks. Our findings highlight the benefits of certain model architectures, training techniques, and data strategies, including the use of high-fidelity synthetic data and multi-stage training with a data curriculum. Notably, we find that a data curriculum enables models to learn challenging geometry understanding tasks which they fail to learn from scratch. Leveraging these insights, we develop Euclid, a family of models specifically optimized for strong low-level geometric perception. Although purely trained on synthetic multimodal data, Euclid shows strong generalization ability to novel geometry shapes. For instance, Euclid outperforms the best closed-source model, Gemini-1.5-Pro, by up to 58.56% on benchmark tasks and 10.65% across the tasks.
Project Overview
We aim to study the challenges of LLVP in MLLMs, take steps to understand the root cause of their performance, and improve the models' capabilities in this area.
Our contribution consists of a complete package of evaluation benchmarks, synthetic data generation pipeline, and a family of models specifically optimized for strong low-level geometric perception.
- Geoperception Benchmark: We introduce a new benchmark dataset, Geoperception, derived from the Geometry-3K corpus, specifically designed to evaluate MLLMs' ability to accurately perceive surface-level geometric information without requiring complex inference or reasoning. Our benchmark reveals shortcomings in precise geometric perception across all leading vision-language MLLMs, both closed and open-source.
- Empirical Study and Synthetic Data Engine: To investigate the root cause of this performance, we conduct a detailed empirical exploration of MLLM architecture and training strategies. To aid in our investigation, we develop a synthetic data engine capable of generating high-fidelity visual descriptions of geometric elements. This study leads to key insights, such as the importance of certain architectural choices and the use of curriculum-based, multi-stage training with progressively more complex visual descriptions for improving low-level visual perception.
- Euclid Model: Leveraging the insights from our exploration and our synthetic data engine, we train Euclid, a series of MLLMs tailored for high-quality geometric LLVP. Although purely trained on synthetic multimodal data with simple geometry shapes, Euclid generalizes strongly to the real-world geometry images from Geoperception benchmark, for instance, outperforming the best closed-source model, Gemini-1.5-Pro, by up to 58.56% on certain benchmark tasks and 10.65% across the tasks.
Geoperception Benchmark
Geoperception is sourced from the Geometry-3K corpus, but undergoes an additional filtering process with GPT-4o-mini to ensure the presence of all geometric elements in the image. Four examples from Geoperception are shown below:
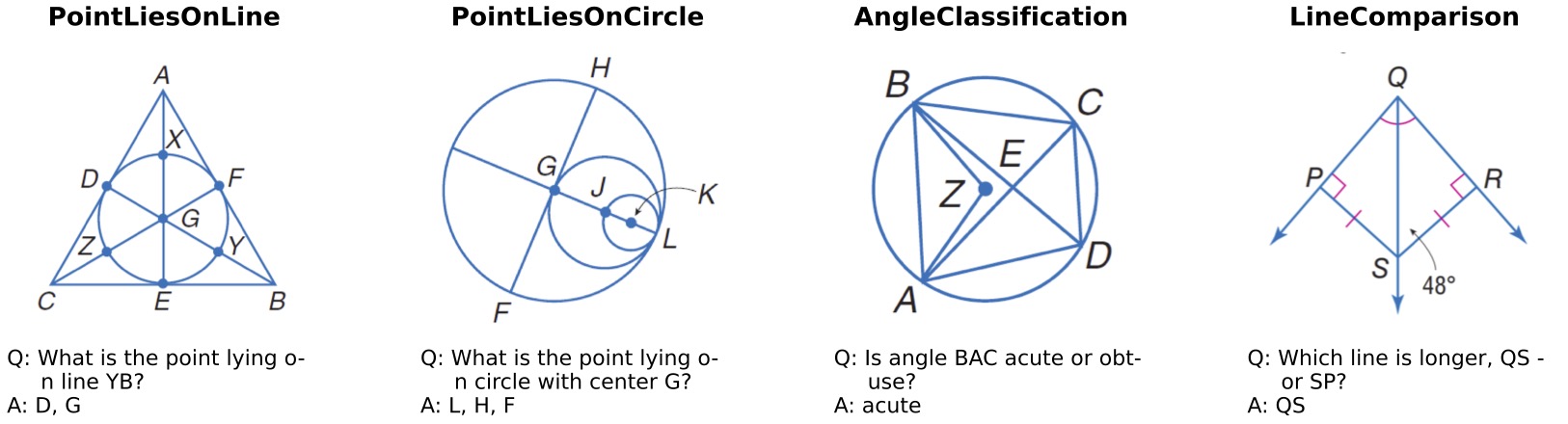
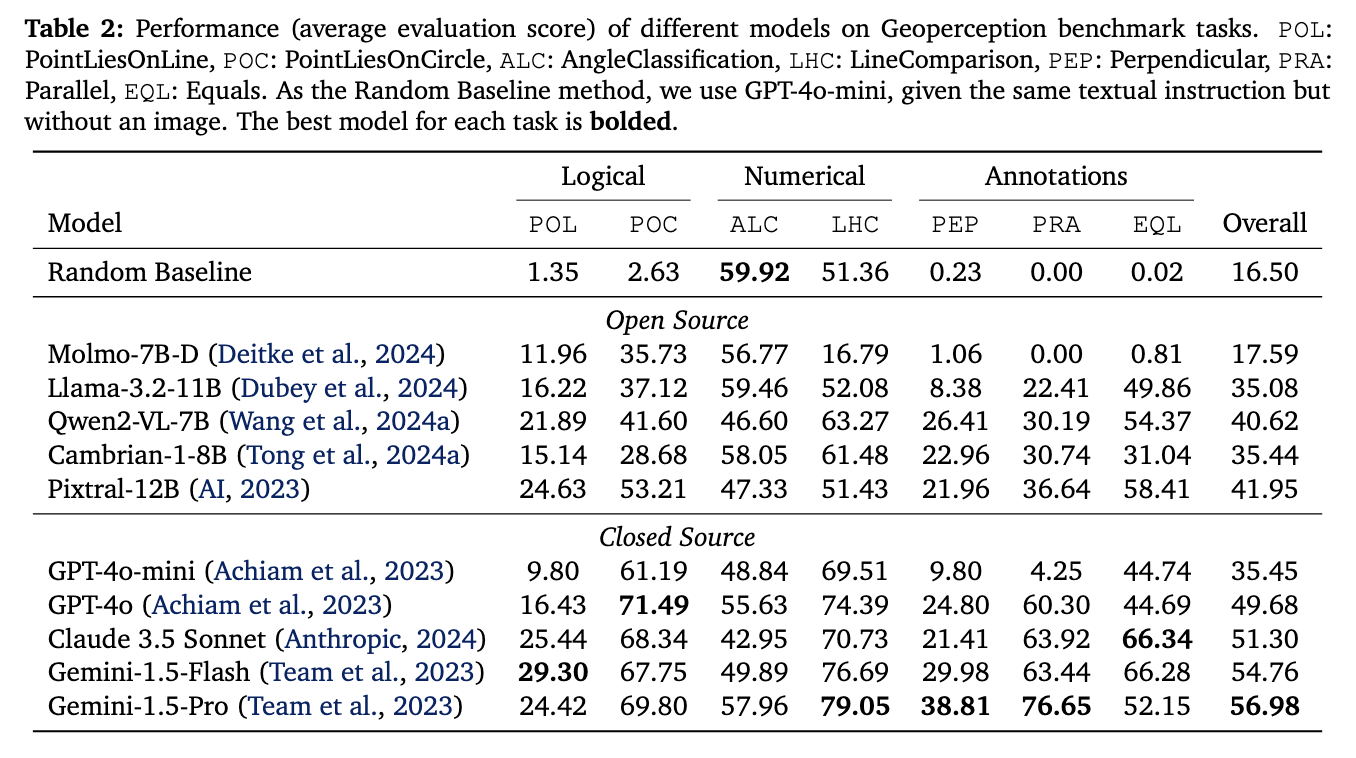
We evaluate leading open- and closed-source MLLMs, and report accuracy below. Despite the simplicity of Geoperception for humans, it remains a considerable challenge for even the most advanced commercial MLLMs. Closed-source models generally outperform open-source models.
Empirical Study on MLLM Design Space
We hypothesize the inability of today's MLLMs to effectively perceive basic geometric annotations and relationships stems from two factors:
- The lack of high-fidelity geometric visual perception training data.
- The problem of their model architectures and training strategy.
Overcoming the Lack of High-Fidelity Geometric Visual Perception Training Data
To provide sufficient high-fidelity training datasets, we develop a dataset generation engine to programmatically produce geometry shapes. Our geometry shape generation engine is built on AlphaGeometry. Given an input formal language describing a geometry shape, the geometry engine will first check the validity of the geometry shape. Then it will create numerical positions for all points following the restrictions given by the input. After the creation of all points, it will connect the line as specified in the input. To avoid inductive bias during training (e.g. point A is always on top of a triangle), letters are first picked from a letter pool (e.g. all 26 capital letters) and then randomly assigned to each point.

Next, we will empirically explore the model architecture and training strategy to improve the performance of MLLMs on Geoperception.
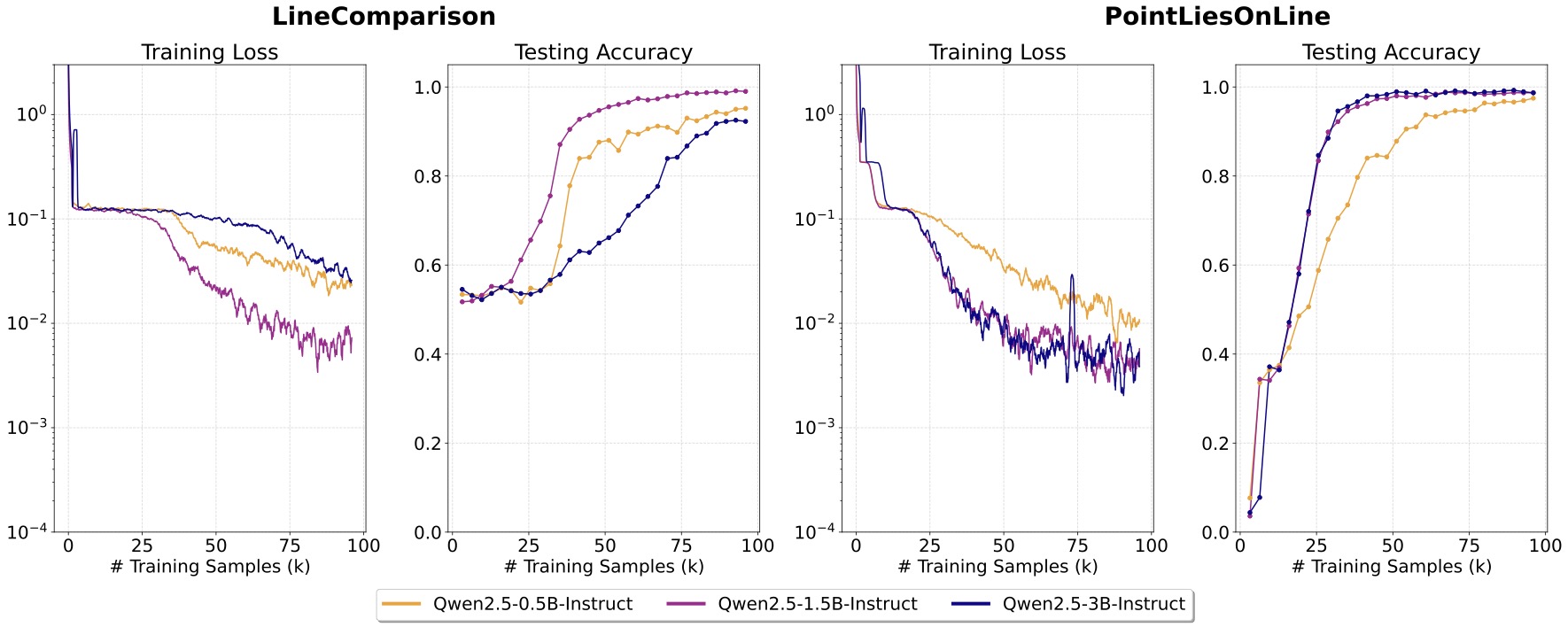
Lesson 1: Under the same training dataset, scaling LLM sizes does not lead to better performance.
We first vary the sizes of LLMs, Qwen-2.5~\citep{qwen2.5} in a range of 0.5B, 1.5B, and 3B while keep other components consistent. The result is shown below. We do not observe an obvious trend that larger LLMs can learn such low-level visual perception task faster or better. Moving forward, we will use Qwen-2.5-1.5B to continue our exploration.
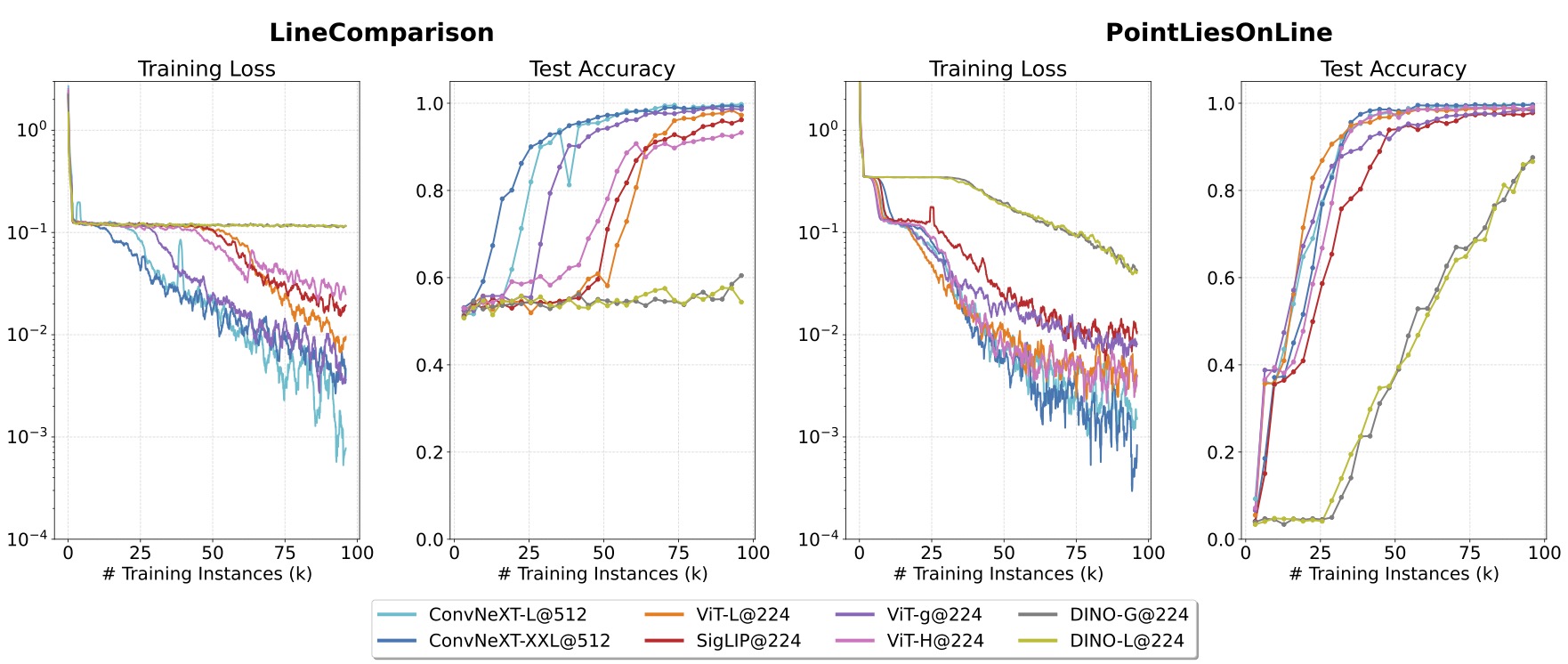
Lesson 2: CNN architecture performs better than ViT.
We then study the choice of visual encoder architectures, including two families of architectures: Vision Transformer (ViT) and ConvNeXT; as well as two visual representation learning objectives: language-supervised learning and self-supervised learning. ConvNeXT-Large shows superior learning performance with the vision transformers which are 3-5 times larger.
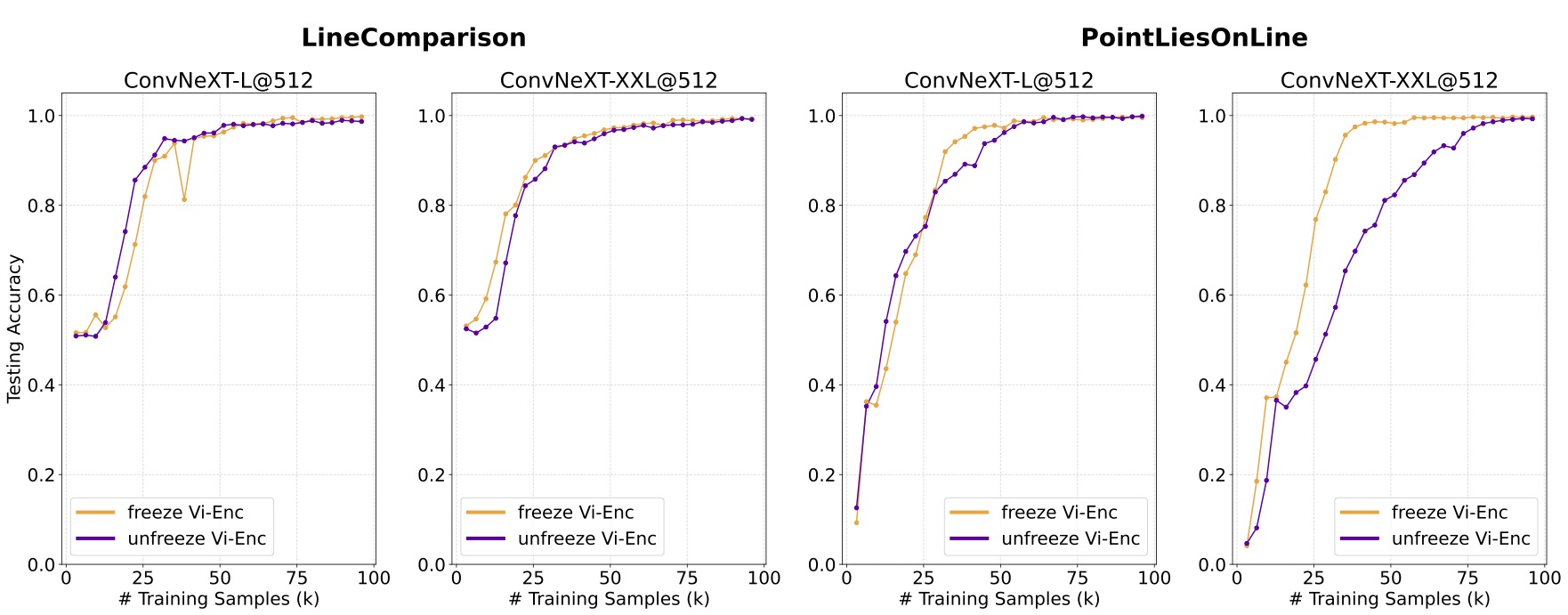
Lesson 3: Tuning vision encoder does not provide significant help.
We next study the effect of tuning versus freezing the visual encoder. Below, we show the testing accuracy curves of tuning and freezing visual encoders. We find that compared with using a frozen encoder, tuning the visual encoder does not help the model learn low-level geometry relationships faster or better. In what follows, we will freeze the encoder for simplicity.
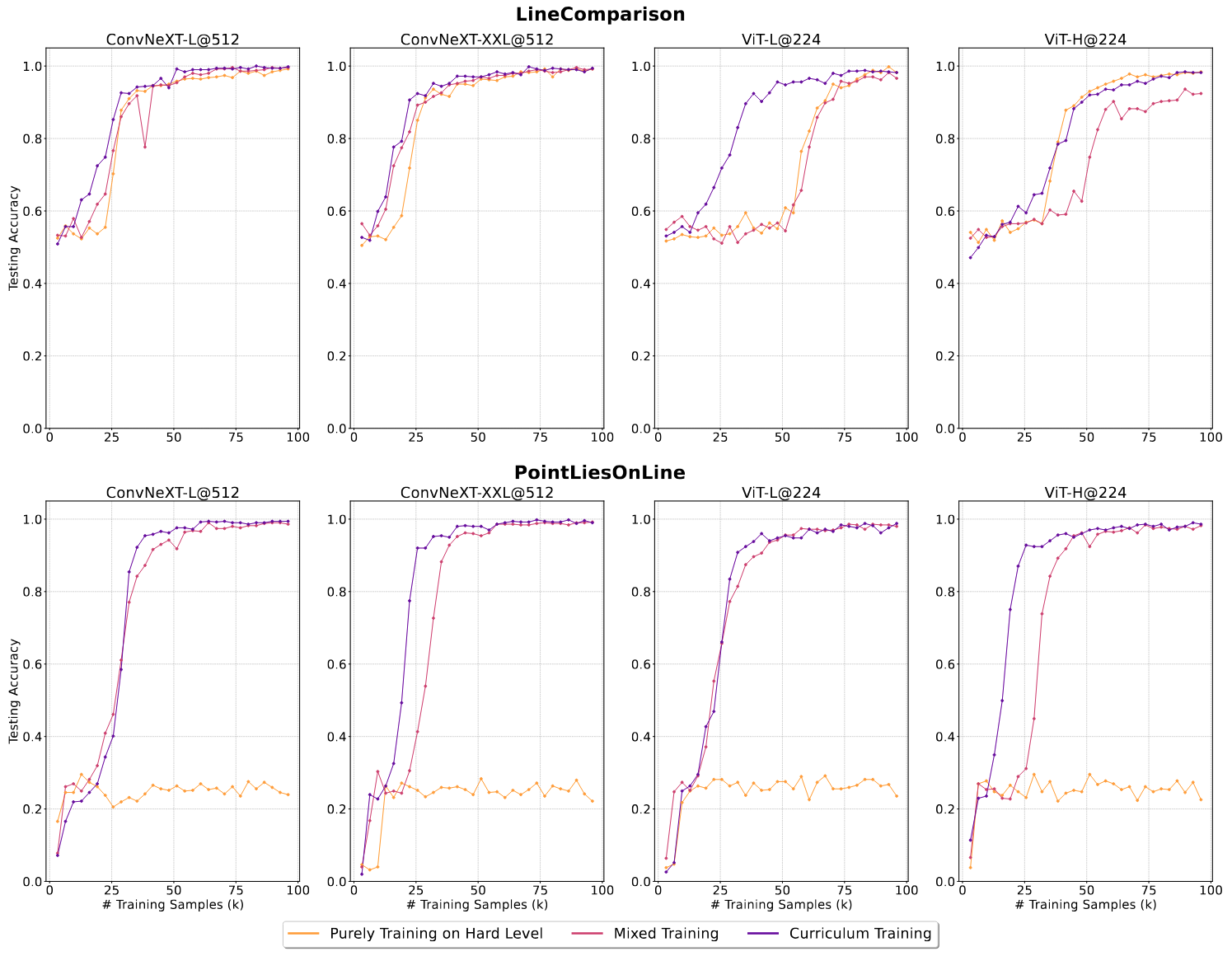
Lesson 4: Curriculum learning unleashes full potential.
We train the model sequentially from simple to more complex shapes and compare testing accuracy just on hard level tasks. During training, we monitor the model's performance and dynamically adjust the distribution of training data (i.e., the curriculum stage) based on this performance.
Euclid
In this section, we take all of the lessons we learned in the previous sections and train Euclid, a family of MLLMs specifically designed for strong geometric LLVP.
For models, we select the best visual encoder architecture we found in our investigation, ConvNeXt, including ConvNeXt-Large@512 and ConvNeXt-XXLarge@512, and keep the same multimodal connector (2 layers MLP) and LLM (Qwen2.5-1.5B-instruct). We also employ curriculum learning to train the model. The performance of of our models is shown below.
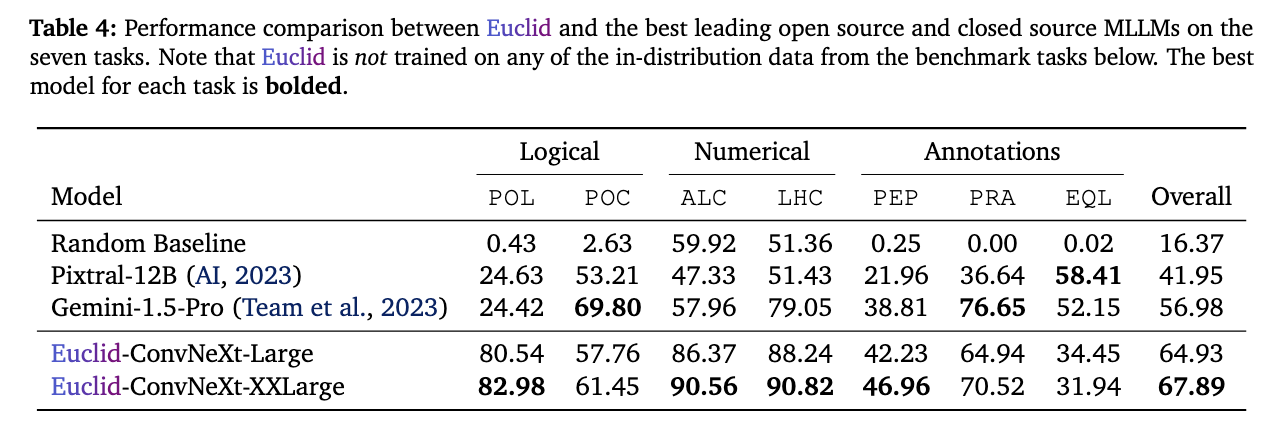
Overall, although only trained on very simple synthetic geometry shapes, and using only a 1.5B language model, Euclid significantly outperforms current leading MLLMs in most of the tasks, showing strong generalization abilities on real-world geometry LLVP. Notably, in the \texttt{PointLiesOnLine} task, which is particularly challenging for existing MLLMs, Euclid achieves up to 82.98% accuracy, more than three times the performance of Gemini-1.5-Pro. On all both numerical tasks, \texttt{LineComparison} and \texttt{AngleClassification}, Euclid keeps superior performance. However, on three annotation tasks, Euclid's performance is limited. We hypothesis this is due to the limited setting of our annotation types and styles, making the model hard to generalize to diverse human geometry annotations.
Conclusion
In this work, we highlight the importance of accurate low-level visual perception (LLVP) in MLLMs. To this end, we first introduce Geoperception, a large-scale multimodal benchmark focused exclusively on geometry-domain visual perception. We evaluate leading MLLMs on Geoperception, find that even top models such as Gemini-1.5-Pro struggle significantly it, although it is straightforward for humans. We then conduct an empirical study to explore the design space of MLLM training and architectures using the dataset generated by a geometric high-fidelity synthetic-data engine that we develop. Our study indicate that convolutional neural network visual encoders outperform vision transformers in our tasks; tuning the visual encoder generally enhances performance; and employing a curriculum-based training approach yields much more model potential than direct task training. Based on insights from this study, we develop Euclid, a model trained purely on high-fidelity synthetic generated data, which generalizes effectively to real-world geometric shape understanding tasks, surpassing the leading MLLMs by a substantial margin.
BibTeX
@article{zhang2024euclid,
title={Euclid: Supercharging Multimodal LLMs with Synthetic High-Fidelity Visual Descriptions},
author={Zhang, Jiarui and Liu, Ollie and Yu, Tianyu and Hu, Jinyi and Neiswanger, Willie},
journal={arXiv preprint arXiv:2412.08737},
year={2024}
}